mysql は Ver 14.14 Distrib 5.6.43 ですが、5.5 でも起きるみたいです。https://bugzilla.redhat.com/show_bug.cgi?id=724894 の Here is the patch found on the bacula mantis: に回答がありました。只、私の make_mysql_tables スクリプトは 322行目ではなく、325行目でしたので、@@ -322,12 +322,12 @@ の部分は @@ -325,12 +325,12 @@ になります。その訂正した分のパッチは
※Tripwire設定ファイル(テキスト版)を復元する場合 # twadmin -m f -c /etc/tripwire/tw.cfg > /etc/tripwire/twcfg.txt
# gedit /etc/tripwire/twpolmake.pl
#!/usr/bin/perl # Tripwire Policy File customize tool # ---------------------------------------------------------------- # Copyright (C) 2003 Hiroaki Izumi # This program is free software; you can redistribute it and/or # modify it under the terms of the GNU General Public License # as published by the Free Software Foundation; either version 2 # of the License, or (at your option) any later version. # This program is distributed in the hope that it will be useful, # but WITHOUT ANY WARRANTY; without even the implied warranty of # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the # GNU General Public License for more details. # You should have received a copy of the GNU General Public License # along with this program; if not, write to the Free Software # Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA. # ---------------------------------------------------------------- # Usage: # perl twpolmake.pl {Pol file} # ---------------------------------------------------------------- # $POLFILE=$ARGV[0]; open(POL,"$POLFILE") or die "open error: $POLFILE" ; my($myhost,$thost) ; my($sharp,$tpath,$cond) ; my($INRULE) = 0 ; while (<POL>) { chomp; if (($thost) = /^HOSTNAME\s*=\s*(.*)\s*;/) { $myhost = `hostname` ; chomp($myhost) ; if ($thost ne $myhost) { $_="HOSTNAME=\"$myhost\";" ; } } elsif ( /^{/ ) { $INRULE=1 ; } elsif ( /^}/ ) { $INRULE=0 ; } elsif ($INRULE == 1 and ($sharp,$tpath,$cond) = /^(\s*\#?\s*)(\/\S+)\b(\s+->\s+.+)$/) { $ret = ($sharp =~ s/\#//g) ; if ($tpath eq '/sbin/e2fsadm' ) { $cond =~ s/;\s+(tune2fs.*)$/; \#$1/ ; } if (! -s $tpath) { $_ = "$sharp#$tpath$cond" if ($ret == 0) ; } else { $_ = "$sharp$tpath$cond" ; } } print "$_\n" ; } close(POL) ;

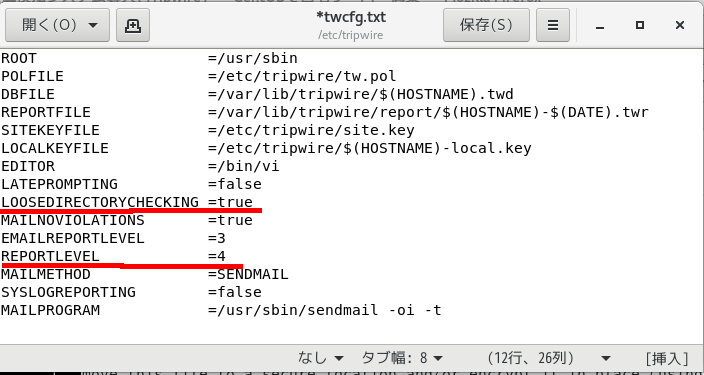
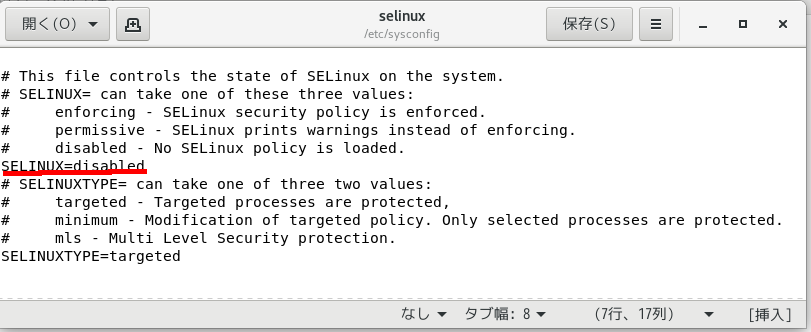
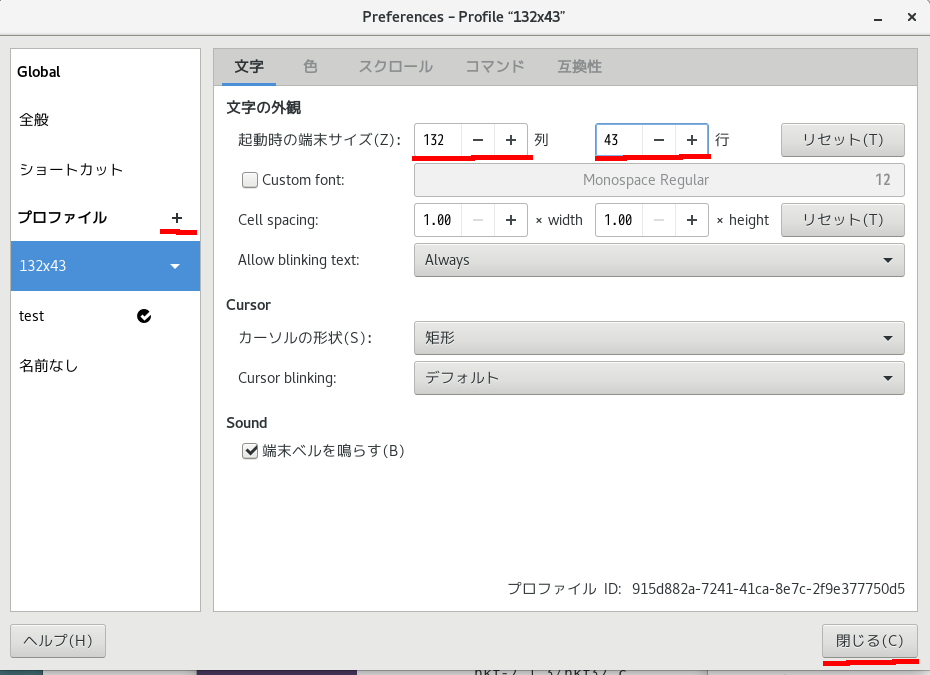
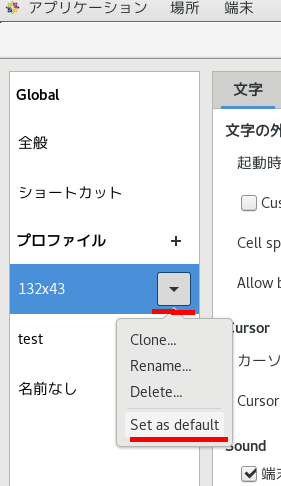
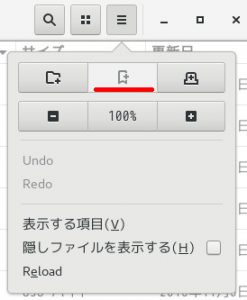 赤線を引いてある所がブックマークを設定するところ
赤線を引いてある所がブックマークを設定するところ