
linuxのthunderbird(Ver 68.12.0)でメールサーバーにディレクトリーを作成しても表示されない。
下記の様に設定すると表示される様になる。
編集 → アカウント設定 → 左にあるサーバー設定をクリック。右のサーバー設定の右の方にある詳細をクリック。メールユーザー名にある“購読しているフォルダーのみを表示する”のチェックを外す。thunderbirdを再起動すると表示された。
linuxのthunderbird(Ver 68.12.0)でメールサーバーにディレクトリーを作成しても表示されない。
下記の様に設定すると表示される様になる。
編集 → アカウント設定 → 左にあるサーバー設定をクリック。右のサーバー設定の右の方にある詳細をクリック。メールユーザー名にある“購読しているフォルダーのみを表示する”のチェックを外す。thunderbirdを再起動すると表示された。
今日、メールのログ(/var/log/maillog)をチェックしていたら、ログに 45.125.65.*(実際は二つのIP、書くと避けて送られるので、又このIPは香港に割り当てられいる)から1893回の記録があり、全てログイン失敗になっていた。1回の接続で3つのログが記録されるので、両方のIPで5日間で631回、1日で126回以上のログインが試みられていた。又、141.98.10.*の3つのIPからも583回のログインがあった。これはリトアニアに割り当てられている。ので、この5つのIPを/root/deny_ipとして登録し、設定を反映するために sh iptables.sh を行った。
状態:全角・半角を押しても日本語や直接入力に切り替わらない。でも右上の “あ” や” _A” をクリックし、入力モードから ひらがなや直接入力を選ぶと変更される。
色々とgoogle先生に聞いて調べたがどれもインストールされていたり、設定されていたりしている!!!なんで変更できない、いちいちクリックするのでは1回で終わらないし、タイピングの途中でマウス操作は煩わしい。色々やって見ると
Alt+@ と Alt+Shift+@ で切り替わった。他の3つは切り替わらない。Altとの組み合わせのみが切り替わる。
原因は未だに不明だが、ともかく Alt+@ で切り替わるので良しとしている。
理由がわかる方がいれば教えてください(下にあるコメントするから)
なんでこんなに変なメールがいっぱい来るの?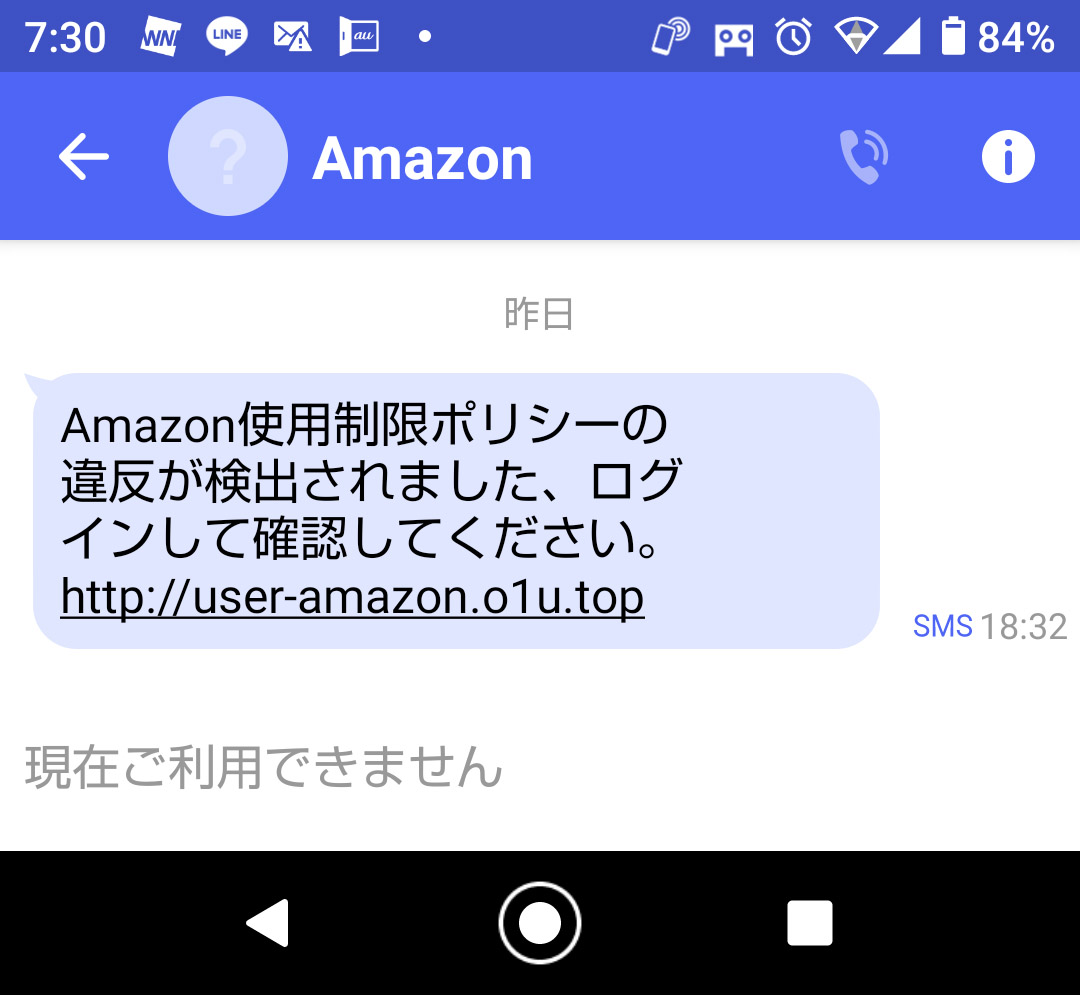
これがその内容である。何度も言うようだが、必ずドメインを確認すること!!
このリンク先のドメインは o1u.top だ。なのでここはアマゾンでは無い!!
アマゾンのドメインは私の知る限り amazon.co.jp か amazon.com である。
ドメインの前にあるuser-amazon はホスト名で誰でも勝手に作れる。でもドメインは登録が必要なので簡単にはごまかせない。e-mailでhtmlを有効にしていたらリンク先に適当な文字を充てられ、リンク先と表示されている文字が違うように出来るが、ショートメールでは出来ないので、リンク先のドメインは表示されているので気を付ければ良いだけ。余談だが o1u なんていかにも怪しげだと思うが。
これでログインしようものなら、あなたのユーザー名(ID)とパスワードは完全に盗まれる。調べてみると、これは中国からだ。中国はこんな輩が多いから、私のサーバーでは中国からのパケットは一切拒否している。
sambaのグループは以下の方針
1:個人用directoryは作らない
2:public directory も作らない
3:社員全員がアクセスできるdirectoryを作る
4:部門毎にアクセスできるdirectoryを作る
という方針でsmb.confを設定して行きますが、ほぼ http://centossrv.com /samba.shtml
からの受け売りです。
# gedit /etc/samba/smb.conf
[global]
unix charset = UTF-8 ← 追加(Linux側日本語文字コード)
dos charset = CP932 ← 追加(Windows側日本語文字コード)
mangled names = no ← 追加(長いファイル名の文字化け対処)
vfs objects = catia ← 追加(上記対処でファイルアクセス不可になる一部文字の置換)
catia:mappings = 0x22:0xa8,0x2a:0xa4,0x2f:0xf8,0x3a:0xf7,0x3c:0xab,0x3e:0xbb,0x3f:0xbf,0x5c:0xff,0x7c:0xa6 ← 追加(上記対処でファイルアクセス不可になる一部文字の置換)
# workgroup = NT-Domain-Name or Workgroup-Name
workgroup = WORKGROUP ← 変更(Windowsのワークグループ名を指定)
※マイコンピュータのプロパティ⇒コンピュータ名タブ内のワークグループ欄を参照
; hosts allow = 192.168.1. 192.168.2. 127.
hosts allow = 192.168.11. 127. ← 追加(内部からのみアクセスできるようにする,IPはローカルネットワークに合わせる)
# If you want to automatically load your printer list rather
# than setting them up individually then you’ll need this
; load printers = yes ← 行頭に;を追加(プリンタ共有無効化)※Sambaでプリンタを共有しない場合
load printers = no ← 追加(プリンタ共有無効化)※Sambaでプリンタを共有しない場合
disable spoolss = yes ← 追加(プリンタ共有無効化)※Sambaでプリンタを共有しない場合
[kinryo]
comment = 社員全員がアクセスできる
path = /SmbData/kinryo
public = yes
writable = yes
force group = kinryo
force create mode = 770
force directory mode = 770
valid users = @kinryo
#共有ディレクトリのごみ箱機能追加(ここから) ※ファイル削除時に自動的にごみ箱へ移動されるようにする
vfs objects = recycle ← ごみ箱の有効化
recycle:repository = .recycle ← ごみ箱のディレクトリ名
recycle:keeptree = no ← ごみ箱へ移動時にディレクトリ構造を維持しない
recycle:versions = yes ← 同名のファイルがごみ箱にある場合に別名で移動
recycle:touch = no ← ごみ箱へ移動時にタイムスタンプを更新しない
recycle:maxsize = 0 ← ごみ箱へ移動するファイルのサイズ上限(0:無制限)
recycle:exclude = *.tmp ~$* ← ここで指定したファイルはごみ箱へ移動せずに即削除する
共有ディレクトリのごみ箱機能追加(ここまで)
[kinryo]の説明、部門毎はこのように作成。ユーザーを指定し、部門毎のグループを作っておく。又このグループはシステム上のグループである。先ずはグループを作る
# groupadd 追加するグループ名
次にユーザーをグループに入れる。下の -aG はオリジナルのグループは変更せず、新しいグループにも入れる設定
# usermod -aG 所属するグループ名 ユーザー名
これを繰り返し、同一ユーザーを複数のグループに所属させる事もできます。
smb.confを変更したので
# systemctl restart smb
# systemctl restart nmb
smb.conf に作ったdirectory を/SmbData の下に作る。ここではkinryo だけですが、各部門毎のdirectory を作って行きます。
# cd /SmbData
# mkdir smb.conf内に作ったdirectory名
# chmod 770 smb.conf内に作ったdirectory名
# chgrp -R グループ名 smb.conf内に作ったdirectory名
これを作ったdirectory分繰り返します。
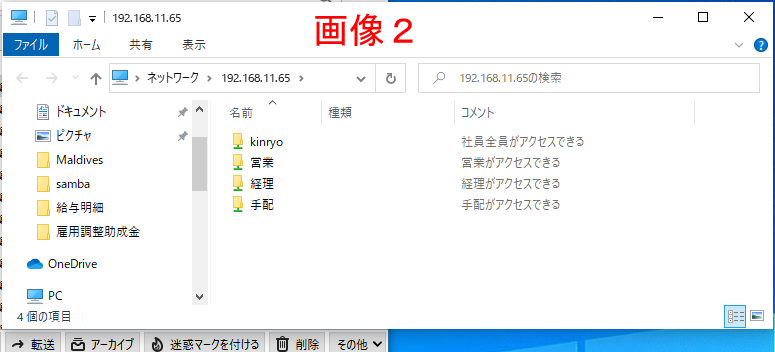
これで、Windowからアクセス出来る筈です。
ウィンドウアイコンの隣にある”ここに入力して検索”に
\\192.168.11.65 (\は半角¥)
と入力しエンターを押すと作ったグループホルダーが見える筈です。

drbdの設定は終わったのですが、sambaの起動状況を判断してprimary, secondaryの切り替えを行いたいのですが、この方法が判りませんが、下記の方法でエラーが出ていないので、この設定を入れています。systemctl status smb 同様に nmb も行い起動していないことを確認、又、ststemctl disable smb 同様に nmb も行い、ホストの起動時に走らないようにする。
# pcs resource create SAMBA systemd:smb –group smbgroup
# pcs resource create NAMED systemd:nmb –group smbgroup
#pcs status
Cluster name: mycluster
Stack: corosync
Current DC: smb1 (version 1.1.21-4.el7-f14e36fd43) - partition with quorum
Last updated: Sun Oct 18 08:14:05 2020
Last change: Sun Oct 18 08:07:39 2020 by root via cibadmin on smb0
2 nodes configured
7 resources configured
Online: [ smb0 smb1 ]
Full list of resources:
Resource Group: smbgroup
vipcheck_res (ocf::myres:VIPcheck): Started smb0
VirtualIP (ocf::heartbeat:IPaddr2): Started smb0
FS_DRBD0 (ocf::heartbeat:Filesystem): Started smb0
SAMBA (systemd:smb): Started smb0
NAMED (systemd:nmb): Started smb0
Master/Slave Set: MS_DRBD0 [DRBD0]
Masters: [ smb0 ]
Slaves: [ smb1 ]
Failed Resource Actions:
* SAMBA_monitor_60000 on smb0 'not running' (7): call=44, status=complete, exitreason='',
last-rc-change='Sun Oct 18 08:07:08 2020', queued=0ms, exec=0ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabledSAMBA (systemd:smb): Started smb0 と NAMED (systemd:nmb): Started smb0 がある事を確認
# systemctl stop smb
# pcs status
前略
Resource Group: smbgroup
vipcheck_res (ocf::myres:VIPcheck): Started smb0
VirtualIP (ocf::heartbeat:IPaddr2): Started smb0
FS_DRBD0 (ocf::heartbeat:Filesystem): Started smb0
SAMBA (systemd:smb): FAILED smb0
NAMED (systemd:nmb): Stopped
Master/Slave Set: MS_DRBD0 [DRBD0]
Masters: [ smb0 ]
Slaves: [ smb1 ]
Failed Resource Actions:
* SAMBA_monitor_60000 on smb0 'not running' (7): call=56, status=complete, exitreason='',
last-rc-change='Sun Oct 18 08:21:13 2020', queued=0ms, exec=0ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
smb0 が FAILED になっているが smb0 のままで、smb1 に移行しないが、少したって pcs status をやると smb0 が起動している。つまり少しの間 smb0 が落ちているが、自動的に再起動している。なのでいいとする。又、Failed Resource Actions: を消すには
# pcs resource cleanup
# pcs status
で見るとエラーが消えている筈
samba関連の設定ご存知なら是非、御教授ください。
ELRepoリポジトリーのインストール
# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
DRBDのインストール
# yum -y install kmod-drbd84
drbdに割り当てるディスクはLVMで作成しそれぞれ /dev/vdd になっている
DRBDリソース(r0.res)設定ファイルの作成
# gedit /etc/drbd.d/r0.res
resource r0 { ← DRBDリソース名をr0とする device /dev/drbd0; meta-disk internal; on smb0 { ← node1ホスト名(「uname -n」コマンドで表示される名前) disk /dev/vdd; ← node1論理ボリューム名 address 192.168.11.60:7780; ← node1IPアドレス } on smb2 { ← node2ホスト名:本来はsmb1(「uname -n」コマンドで表示される名前) disk /dev/vdd; ← node2論理ボリューム名 address 192.168.11.61:7780; ← node2IPアドレス } }
メタデーターの作成
# drbdadm create-md r0 (注:データーのあるディスクに行ってもデータは消えない)
md_offset 499826814976
al_offset 499826782208
bm_offset 499811528704
Found some data
==> This might destroy existing data! <==
Do you want to proceed?
[need to type ‘yes’ to confirm] yes
initializing activity log
initializing bitmap (14896 KB) to all zero
Writing meta data…
New drbd meta data block successfully created.
これは前に何か使用していたディスクなので、Do you want to proceed? と聞いているが、マッサラなディスクだと聞いてこない。
ここまでを smb1でもやる
drbdの起動
# systemctl start drbd
smb1も起動しないとプロンプトに戻ってこない。
また、ここまでをsmb1でもやる
version: 8.4.11-1 (api:1/proto:86-101)
GIT-hash: 66145a308421e9c124ec391a7848ac20203bb03c build by mockbuild@, 2020-04-05 02:58:18
0: cs:Connected ro:Secondary/Secondary ds:UpToDate/UpToDate C r-----
ns:0 nr:0 dw:0 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0cs が connected で、ro が両方共 Secondary(待機状態)になっている事。
smb1側でも行って同じになっている事。smb0側で
# drbdadm primary all
# cat /proc/drbd
前略
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
後略
roがPrimary/Secondaryになっている事。smb1側でも行ってroが Secondary/Primaryになっている事。smb0 で DRBDデバイス(/dev/drbd0)にファイルシステム作成
# mkfs.xfs /dev/drbd0
meta-data=/dev/drbd0 isize=512 agcount=4, agsize=30506075 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=122024299, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=59582, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# mount /dev/drbd0 /SmbData/
# df
devtmpfs 2006988 0 2006988 0% /dev
tmpfs 2022644 93032 1929612 5% /dev/shm
tmpfs 2022644 9764 2012880 1% /run
tmpfs 2022644 0 2022644 0% /sys/fs/cgroup
/dev/vda1 19520512 6486968 13033544 34% /
/dev/vdc 15718400 5144496 10573904 33% /Download
tmpfs 404532 4 404528 1% /run/user/42
tmpfs 404532 36 404496 1% /run/user/0
/dev/drbd0 487858868 32992 487825876 1% /SmbDataSmbDataにファイルを作って出来ているか確認
# touch /SmbData/test.txt
# ll /SmbData/
合計 0
-rw-r–r– 1 root root 0 10月 18 04:36 test.txt
次に、smb0をsecondayにし、smb1をprimaryにするが、マウントを外さないとならない
# umount /SmbData
dfでマウントされていない事を確認後
# drbdadm secondary all
smb1で
# drbdadm primary all
# cat /proc/drbd
で、ro:Secondary/Primary になっている事を確認後、マウントしdfでマウントされている事を確認後、llでファイルがsmb1にもあるか確認
# mount /dev/drbd0 /mnt
# df
<pre class="wp-block-code"><code><span style="color: #ff6600;">devtmpfs 2006988 0 2006988 0% /dev
tmpfs 2022644 93032 1929612 5% /dev/shm
tmpfs 2022644 9764 2012880 1% /run
tmpfs 2022644 0 2022644 0% /sys/fs/cgroup
/dev/vda1 19520512 6486968 13033544 34% /
/dev/vdc 15718400 5144496 10573904 33% /Download
tmpfs 404532 4 404528 1% /run/user/42
tmpfs 404532 36 404496 1% /run/user/0
/dev/drbd0 487858868 32992 487825876 1% /SmbData</span></code></pre># ll /SmbData
合計 0
-rw-r–r– 1 root root 0 10月 18 04:36 test.txt
そしてumount後、smb1をsecondaryにする
# umount /SmbData
# drbdadm secondary all
smb0をpromaryにし、
# drbdadm primary all
smb0とsmb1で cat /Proc/drbd を行いsmb0がprimary, smb1がsecondaryになっている事を確認
Resource Group: smbgroup
vipcheck_res (ocf::myres:VIPcheck): Started smb0
VirtualIP (ocf::heartbeat:IPaddr2): Started smb0
Master/Slave Set: MS_DRBD0 [DRBD0]
Masters: [ smb0 ]
Slaves: [ smb1 ]/dev/drbd0をxfs形式で/mntディレクトリへマウントするクラスタリソースをFS_DRBD0という名前で追加
# pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/SmbData fstype=xfs –group smbgroup
# pcs resource show
Resource Group: smbgroup
vipcheck_res (ocf::myres:VIPcheck): Started smb0
VirtualIP (ocf::heartbeat:IPaddr2): Started smb0
FS_DRBD0 (ocf::heartbeat:Filesystem): Started smb0
Master/Slave Set: MS_DRBD0 [DRBD0]
Masters: [ smb0 ]
Slaves: [ smb1 ]FS_DRBD0があることを確認
DRBDがmaster側のノードでリソースグループ(smbgroup)を起動する
# pcs constraint order promote MS_DRBD0 then start smbgroup
Adding MS_DRBD0 smbgroup (kind: Mandatory) (Options: first-action=promote then-action=start)
DRBDがMaster側のノードでFS_DRBD0リソースを起動する
# pcs constraint colocation add FS_DRBD0 MS_DRBD0 INFINITY with-rsc-role=Master
# pcs constraint order promote MS_DRBD0 then start FS_DRBD0
Adding MS_DRBD0 FS_DRBD0 (kind: Mandatory) (Options: first-action=promote then-action=start)
smb0とsmb1で df をやって、smb0でSmbDataがマウントされていて、smb1側ではマウントされていない事を確認。smb0をhalt
# halt -p
smb1側で
# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: smb1 (version 1.1.21-4.el7-f14e36fd43) - partition with quorum
Last updated: Sun Oct 18 07:11:48 2020
Last change: Sun Oct 18 07:02:15 2020 by root via cibadmin on smb0
2 nodes configured
5 resources configured
Online: [ smb1 ]
OFFLINE: [ smb0 ]
Full list of resources:
Resource Group: smbgroup
vipcheck_res (ocf::myres:VIPcheck): Started smb1
VirtualIP (ocf::heartbeat:IPaddr2): Started smb1
FS_DRBD0 (ocf::heartbeat:Filesystem): Started smb1
Master/Slave Set: MS_DRBD0 [DRBD0]
Masters: [ smb1 ]
Stopped: [ smb0 ]
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
smb0がofflineでsmb1がマスターになっていることを確認
# df
で SmbData がマウントされている事を確認後
smb0起動し、pcs statusで両方共オンラインになっている事、マスターはまだ smb1であることを確認
# pcs cluster standby smb1
# pcs status
で smb0 がマスターになっている事を確認
# pcs cluster unstandby smb1
# pcs status
で両方がオンラインになっている事を確認
# df
で smb0側にSmbDataがマウントされている事を確認
ここからやっとHAクラスターの設定に入ります。私は勉強の為にdrbdを同じメインホストのサブホストにやっていますが、本来なら物理的に違うマシンにやるべきです。
例によって http://centossrv.com/pacemaker.shtml を参考に設定して行きます。
前提条件として2つのサーバーを
ホスト名:smb0 IP:192.168.11.60
ホスト名:smb1 IP:192.168.11.61
仮想IPアドレス 192.168.11.65
とし、先ずはホスト名を /etc/hosts の記入します
# echo 192.168.11.60 smb0 >> /etc/hosts
# echo 192.168.11.61 smb1 >> /etc/hosts
必要なプログラムをインストールとpcsdの起動
# yum -y install pacemaker corosync pcs
# systemctl start pcsd
# systemctl enable pcsd
次にクラスターの作成
# passwd hacluster
パスワード2回聞かれるので、入力
ここまでを smb0, smb1の両方で行う。ここからはsmb0で
# pcs cluster auth smb0 smb1 -u hacluster
パスワード聞かれるので入力
smb0: Authorized
smb1: Authorized
# pcs cluster setup –name mycluster smb0 smb1 –force
smb0: Stopping Cluster (pacemaker)…
smb1: Stopping Cluster (pacemaker)…
smb0: Successfully destroyed cluster
smb1: Successfully destroyed cluster
Sending ‘pacemaker_remote authkey’ to ‘smb0’, ‘smb1’
smb1: successful distribution of the file ‘pacemaker_remote authkey’
smb0: successful distribution of the file ‘pacemaker_remote authkey’
Sending cluster config files to the nodes…
smb0: Succeeded
smb1: Succeeded
Synchronizing pcsd certificates on nodes smb0, smb1…
smb0: Success
smb1: Success
Restarting pcsd on the nodes in order to reload the certificates…
smb0: Success
smb1: Success
クラスターノードの起動、自動起動設定、ステイタス確認
# pcs cluster start –all
smb0: Starting Cluster (corosync)…
smb1: Starting Cluster (corosync)…
smb0: Starting Cluster (pacemaker)…
smb1: Starting Cluster (pacemaker)…
# pcs cluster enable –all
smb0: Cluster Enabled
smb1: Cluster Enabled
# pcs status
Cluster name: mycluster
WARNINGS:
No stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: smb1 (version 1.1.21-4.el7-f14e36fd43) – partition with quorum
Last updated: Sat Oct 17 15:14:31 2020
Last change: Sat Oct 17 15:08:48 2020 by hacluster via crmd on smb1
2 nodes configured
0 resources configured
Online: [ smb0 smb1 ] → smb0, smb1 Onlineを確認
No resources
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
pcs statusをsmb1でも確認する
DRBDのアクセスに使用する仮想IPアドレスの設定(smb1でもやる)
# rpm -ivh –nodeps https://osdn.jp/dl/linux-ha/hb-extras-1.02-1.x86_64.rpm
https://osdn.jp/dl/linux-ha/hb-extras-1.02-1.x86_64.rpm を取得中
準備しています… ################################# [100%]
更新中 / インストール中…
1:hb-extras-1.02-1 ################################# [100%]
ln: シンボリックリンク `/usr/lib64/stonith/plugins/external/stonith-wrapper’ の作成に失敗しました: そのようなファイルやディレクトリはありません
警告: %post(hb-extras-1.02-1.x86_64) スクリプトの実行に失敗しました。終了ステータス 1
終了ステータス が1で終わっていますが大丈夫みたい。
# mkdir /usr/lib/ocf/resource.d/myres
# cp /usr/lib64/heartbeat/hb-extras/VIPcheck /usr/lib/ocf/resource.d/myres/
VIPcheckリソースエージェント起動
# pcs resource create vipcheck_res ocf:myres:VIPcheck target_ip=192.168.11.17 count=1 wait=10 –group smbgroup
stonithを無効化
# pcs property set stonith-enabled=false
2ノード構成のためquorumを無効化
# pcs property set no-quorum-policy=ignore
ここまでをsmb1でも行う。
仮想IPアドレス設定
# pcs resource create VirtualIP IPaddr2 ip=192.168.11.65 cidr_netmask=24 op monitor interval=30s –group smbgroup
Assumed agent name ‘ocf:heartbeat:IPaddr2’ (deduced from ‘IPaddr2’)
リソース確認
# pcs resource show
Resource Group: smbgroup
vipcheck_res (ocf::myres:VIPcheck): Started smb0
VirtualIP (ocf::heartbeat:IPaddr2): Started smb0
仮想IPアドレス通信確認
# ping -c 1 192.168.11.65
PING 192.168.11.65 (192.168.11.65) 56(84) bytes of data.
64 bytes from 192.168.11.65: icmp_seq=1 ttl=64 time=0.062 ms
— 192.168.11.65 ping statistics —
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.062/0.062/0.062/0.000 ms
これをsmb1でも行う。
フェイルオーバーが正常に働くか確認
smb0で
# halt
smb1で
# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: smb1 (version 1.1.21-4.el7-f14e36fd43) – partition with quorum
Last updated: Sat Oct 17 16:52:51 2020
Last change: Sat Oct 17 16:51:00 2020 by hacluster via crmd on smb1
2 nodes configured
2 resources configured
Online: [ smb1 ]
OFFLINE: [ smb0 ]
Full list of resources:
Resource Group: smbgroup
vipcheck_res (ocf::myres:VIPcheck): Started smb1
VirtualIP (ocf::heartbeat:IPaddr2): Started smb1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
pinkの所を確認。この時
Failed Resource Actions:
* vipcheck_res_monitor_0 on smb1 ‘not installed’ (5): call=5, status=Not installed, exitreason=”,
等のエラーがあった場合は、原因を除いてから
# pcs resource cleanup
でエラー表示を消去する。smb1でping確認すること
smb0を起動する。pcs status をやってもsmb0はonlineになっているがまだsmb1側が動いている。smb0側でsmb1をスタンバイにして、smb0に移るか確認
# pcs cluster standby smb1
# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: smb1 (version 1.1.21-4.el7-f14e36fd43) – partition with quorum
Last updated: Sat Oct 17 17:24:11 2020
Last change: Sat Oct 17 17:24:04 2020 by root via cibadmin on smb0
2 nodes configured
2 resources configured
Node smb1: standby
Online: [ smb0 ]
Full list of resources:
Resource Group: smbgroup
vipcheck_res (ocf::myres:VIPcheck): Started smb0
VirtualIP (ocf::heartbeat:IPaddr2): Started smb0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
smb1を復帰させる
# pcs cluster unstandby smb1
smb0, smb1がonlineになっていることを確認。
smb0, smb1の両方で仮想IPアドレスにping が通るか確認